
On Monads, Monoids and Endofunctors 1: The monoid
Published:
Spoiler: Category theory has applications in machine learning engineering
Note: The code lives in ianqs - applied_category_theory/1_monoid1
I’m a fan of code abstraction; I like how clean code looks and “feels” - in fact, I think clean and good code is art. In this post, I do not talk about functional vs. imperative vs. object-oriented programming but the mathematical structure in code. You might have heard of concepts such as monads, monoids, functors, etc. At an abstract level, these concepts lay out specific properties that describe how data flows between the various types in your program. The benefit here is that if your code fulfills the requirements laid out by these structures, you get certain guarantees in how you can compose your program(s).
This is the first in a series of blog posts discussing categories in programming that hopefully help you notice patterns and write cleaner code. This series will not be mathematical and assumes no prior knowledge other than python (which you don’t even really need - it just provides a concrete example of what we’re doing).
Throughout the series we expand on code that we establish. It’s important to note that you (and I) have probably written code that fits into these concepts without even realizing it! The point is to highlight these patterns.
1) Initial Project
You’ve just joined a team that runs a distributed hyperparameter search. You have a collection of worker machines, each with a copy of the dataset. Each worker trains a collection of configurations,recording a validation loss for each one. Your boss wants the “best” model, i.e. the one with the lowest validation loss. Concretely: 100 machines, 10 configs each, so 1K runs, and you want the minimum loss out of all of them.
Note: Throughout this post we assume you have some train and validate method implemented. To keep everything runnable, a single run is just:
import random
def run_config(config: dict) -> float | None:
if random.random() < 0.1: # ~10% of runs fail
return None
return random.random() # stand-in for validate(train(config, data))
A run returns a validation loss, or None if it failed (a bad config, an out-of-memory crash, a flaky machine, whatever). Keep an eye on that None; it’s going to follow us around.
1.1) Simple Scenario
Each worker runs its configs and outputs the losses (10 runs -> 1 single best across the macine) to a single “reducer” node (100 machines -> 1 final value), which finds the minimum:
import math
def summarize(losses: list[float | None]) -> float: # a Map
return min((loss for loss in losses if loss is not None), default=math.inf)
def reduce(worker_minimums: list[float]) -> float: # a Reduce
return min(worker_minimums)
Each worker sends up a single float (10 -> 1), and the reducer accumulates all 100 of them to find the winner (100 ->). This is fine! A float is cheap, so the reducer can hold everything in memory without breaking a sweat.
1.2) Complicated Scenario
The situation above is simple. Now two things happen, as they always do.
First, the per-run payload gets bigger (imagine we start carrying around more than a single float), so a single reducer holding all 1K results in memory stops being a good idea. Instead we reduce in a tree: workers 1-10 send to Reducer A, workers 11-20 send to Reducer B, and so on, and a final reducer combines the reducers.
Second, and this is the one that hurts, your boss comes back wanting more than the minimum. They want the mean loss, the variance, the failure rate. The usual “how healthy was this run?” dashboard.
So summarize can no longer just return a float; it has to return a collection of statistics, and reduce has to merge those collections. Here’s a first attempt:
def summarize(losses: list[float | None]) -> dict:
minimum, total, total_sq, count = math.inf, 0.0, 0.0, 0
for loss in losses:
if loss is None:
continue
minimum = min(minimum, loss)
total += loss
total_sq += loss * loss
count += 1
return {"count": count, "total": total, "total_sq": total_sq, "min": minimum}
def reduce(reports: list[dict]) -> dict:
minimum, total, total_sq, count = math.inf, 0.0, 0.0, 0
for r in reports: # the SAME four accumulations, a second time
minimum = min(minimum, r["min"])
total += r["total"]
total_sq += r["total_sq"]
count += r["count"]
return {"count": count, "total": total, "total_sq": total_sq, "min": minimum}
(We carry total and total_sq because that’s all you need to recover the mean and variance at the very end: mean = total / count and variance = total_sq / count - mean**2.)
1.2.1) Messiness
Squint at those two functions. They’re almost the same function, written twice:
summarizefolds over raw floats.reducefolds over dictionaries.
Both re-implement the exact same four accumulations, and both have to remember the exact same set of keys. And whoever sits at the top of the tree is left holding a dict that they have to know how to turn back into stats:
mean = final["total"] / final["count"]
variance = final["total_sq"] / final["count"] - mean ** 2
Now imagine your boss comes back tomorrow (they will) and asks for the max loss too (¯_(ツ)_/¯). You now have to:
- add
maximumtosummarize, - add
maximumtoreduce - update whoever reads the final dict.
If you miss any one of those you drop the max and shit hits the fan, so to speak. Every new summary statistics touches every level of the tree.
1.2.2) So what?
You’re probably now thinking, I’d wrap this in a class instead of the raw dictionaries. And you’d be right (kind of). But cleaning up the “packaging” doesn’t fix all of the problems, which is that the combination logic is duplicated at every level of the tree structure (reduces across reducers). Let’s go deeper and fix the structure instead.
2) A monoid?
We’re going to introduce just a single concept, a monoid, but I wouldn’t bother reading that link until after this post.
What is a monoid? It’s any type that comes with:
- a binary operation, i.e. a way to combine two of them into one
- the binary operation ^ is associative:
(a + b) + c == a + (b + c) - closure in the binary op combining two of them always gives you back one of the same type
- an identity element, a “zero” such that
a + identity == a(like0for+, or1for*).
That’s pretty much it. You’ll notice that our “collection of statistics” kind of wants to be one: combining two summaries should give a summary, the order shouldn’t matter, and an empty summary should be a no-op.
So let’s make it explicit. We’re making a bit of a jump, but I promise the comments carry you through. Meet Summary:
from dataclasses import dataclass
from __future__ import annotations
def run_config(config: dict) -> Summary:
if random.random() < 0.1:
return Summary() # Instead of returning None we return an empty summary
val = random.random()
return Summary.of(loss=val)
@dataclass(frozen=True)
class Summary:
"""Summary statistics over a set of validation losses.
This is a monoid:
- Identity: `Summary()`, an empty summary
- Associative: we've defined + as an associative binary op
- Closed: `+` over Summaries is always a Summary
"""
count: int = 0
total: float = 0.0
total_sq: float = 0.0
minimum: float = math.inf
@classmethod
def of(cls, loss: float) -> Summary:
"""Lift a single loss into a one-element Summary."""
return cls(count=1, total=loss, total_sq=loss * loss, minimum=loss)
def __add__(self, other: Summary) -> Summary:
return Summary(
count=self.count + other.count,
total=self.total + other.total,
total_sq=self.total_sq + other.total_sq,
minimum=min(self.minimum, other.minimum),
)
Three things are going on here, and they line up exactly with the requirements:
Summary(), with all its defaults, is the identity: zero runs, and aminimumofmath.infso thatminnever picks it. Adding it to anything changes nothing.Summary.of(loss)lifts a single measurement into the type, so one loss becomes a summary of one thing.__add__is the associative binary operation, and because it returns aSummary, we’re closed: you can keep folding forever and never leave the type.
The derived stats (mean and variance) aren’t part of the combining at all. They’re just read off at the very end:
@property
def mean(self) -> float:
return self.total / self.count if self.count else math.nan
@property
def variance(self) -> float:
# E[x^2] - E[x]^2
return self.total_sq / self.count - self.mean ** 2 if self.count else math.nan
2.1) Using our monoid
Now watch what happens to the tree. A worker folds its raw losses into one Summary:
def summarize(per_worker_res: Iterable[Summary]) -> Summary:
"""A worker turns its raw losses into a single Summary."""
accum = Summary() # start from the identity
for i, worker_res in enumerate(per_worker_res):
accum = accum + worker_res
return accum
And a reducer? A reducer just folds Summarys into a Summary, which is literally what Python’s sum does once you hand it the identity to start from:
def reduce(summaries: list[Summary]) -> Summary:
return sum(summaries, Summary())
😎 Compare summarize and reduce here to the naive versions above - all the domain logic has moved out of the loops and into Summary. Workers, intermediate reducers, the final reducer, every level is now the same operation, because + is doing the associativity and closure (well, we defined it that way, but y’know):
import random
random.seed(0)
workers = [[run_config({}) for _ in range(10)] for _ in range(100)]
per_worker = [summarize(w) for w in workers] # leaves
groups = [reduce(per_worker[i:i + 10]) for i in range(0, 100, 10)] # middle
final = reduce(groups) # root
print(f"runs: {final.count}")
print(f"min loss: {final.minimum:.4f}")
print(f"mean: {final.mean:.4f}")
print(f"variance: {final.variance:.6f}")
which prints:
runs: 887
min loss: 0.0002
mean: 0.5042
variance: 0.081444
chef’s kiss. Now when our boss inevitably comes back asking for more, we just add a new field to the dataclass, and add an op to the __add__ that is LITERALLY it.
2.2) A retrospective
Notice what actually happened. We managed to “squeeze” all the logic into a single location - the “summarize” and “reduce” don’t know ANYTHING about the underlying type; they just know it implements __add__ and that’s enough. Maybe what’s more important (to me, at least) is that once the data conforms to monoid, the reduction is completely free. We’ve got slightly more code than in naive.py but I’d argue it’s more estensible.
3) Monoids and abstractions
QUICK: Before your eyes gloss over the following diagram, listen to what I’ve got to say. You already know all of the things in the diagram, which is from Wikipedia: monoids.
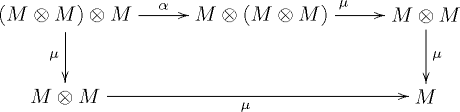
Here M is our type; think of it as Summary. $\bigotimes$ is “put two of them next to each other” and μ is our combine (__add__). The diagram is just the monoid laws drawn as arrows.
On the top line we have three terms; let’s index them 0, 1, and 2. On the bottom line we have two terms, 3 and 4. In between are arrows, which are transformations.
0->1: the arrow $\alpha$ is association, where we can move the parentheses from $(M \bigotimes M) \bigotimes M$ over to $M \bigotimes (M \bigotimes M)$, which is exactly (a + b) + c == a + (b + c), which we introduced earlier.
1->2: we “reduce” $M \bigotimes (M \bigotimes M)$ down to $M \bigotimes M$ by applying $1 \bigotimes \mu$.
0->2: the same thing, but combining the other pair first (the parens are in a different spot).
2->4 && 3->4: the result of the final $\mu$, combining the last pair.
The whole picture says no matter how you sum them up you end up in the same place, which is why we could fold our Summarys up the reduction tree in any order. You’ve been using this diagram all along; you just hadn’t seen it drawn.
Closing Thoughts
This post came about after a discussion with one of my mentees. That mentee was facing something similar, and as someone who has gone through this EXACT problem, I thought I’d write about it and share what I’ve learned.
Also, there’s a bit of a meme saying
A monad is a monoid in the category of endofunctors, what’s the problem?
And we can actually explore what those concepts are by building on what we’ve got. I’ll leave you with the following:
right now we only
count,average,min,variancetheSummary. What if our boss also wants to surface the best model so we can poke around, or filter by a loss range, or transform them? Instead of working with just a list (remember, in prod we might be training these over hundreds of thousands of models), we might want to work over a binary tree or AVL tree of some sort. Abstracting over the container is wherefunctors come in.We sidestepped the
Nonefrom the
import random
def run_config(config: dict) -> float | None:
if random.random() < 0.1: # ~10% of runs fail
return None
return random.random() # stand-in for validate(train(config, data))
but what if we wanted to store why a run failed, instead of swapping it for the identity Summary()? The swap really only works because we’re storing summary statistics, but sometimes it can be useful to store additional information (e.g. did the run fail because of a bad config? the machine OOM-ing?). In this case, we then have to do an if None ... else check over each distributed step: load the shard, train, validate, score, and so on. I would be nice to be able to just hand off the crash and have the later steps know what to do with it; no more if None ... else. This is where monads come in.